Full observability for your coding agent sessions.
Your team ships thousands of lines of code every day — most of it written by coding agents. Kapacitor gives engineering teams one timeline of every session, every repo, every developer. Replay what your agents did, audit what they changed, and collaborate on the runs your team learns from.
Built for teams
One pane of glass for the whole engineering org.
Coding agents are now writing most of your team's code. The
conversation, the tool calls, the diff — it all happens in a terminal
window that closes when the dev hits exit. Kapacitor
captures every session as a stream of events so the whole team can
see what was tried, what shipped, and why.
Org-wide visibility
Every session from every developer, across every repository. Engineering managers stop guessing what their team has been doing with their agents.
Faithful replay
Reconstruct any run end-to-end — prompts, plans, tool calls, edits, and subagent fan-out — without rerunning the agent or paying the tokens twice.
Shared memory
Every session leaves behind facts the next agent can reuse. Your team's collective experience compounds instead of evaporating with each terminal close.
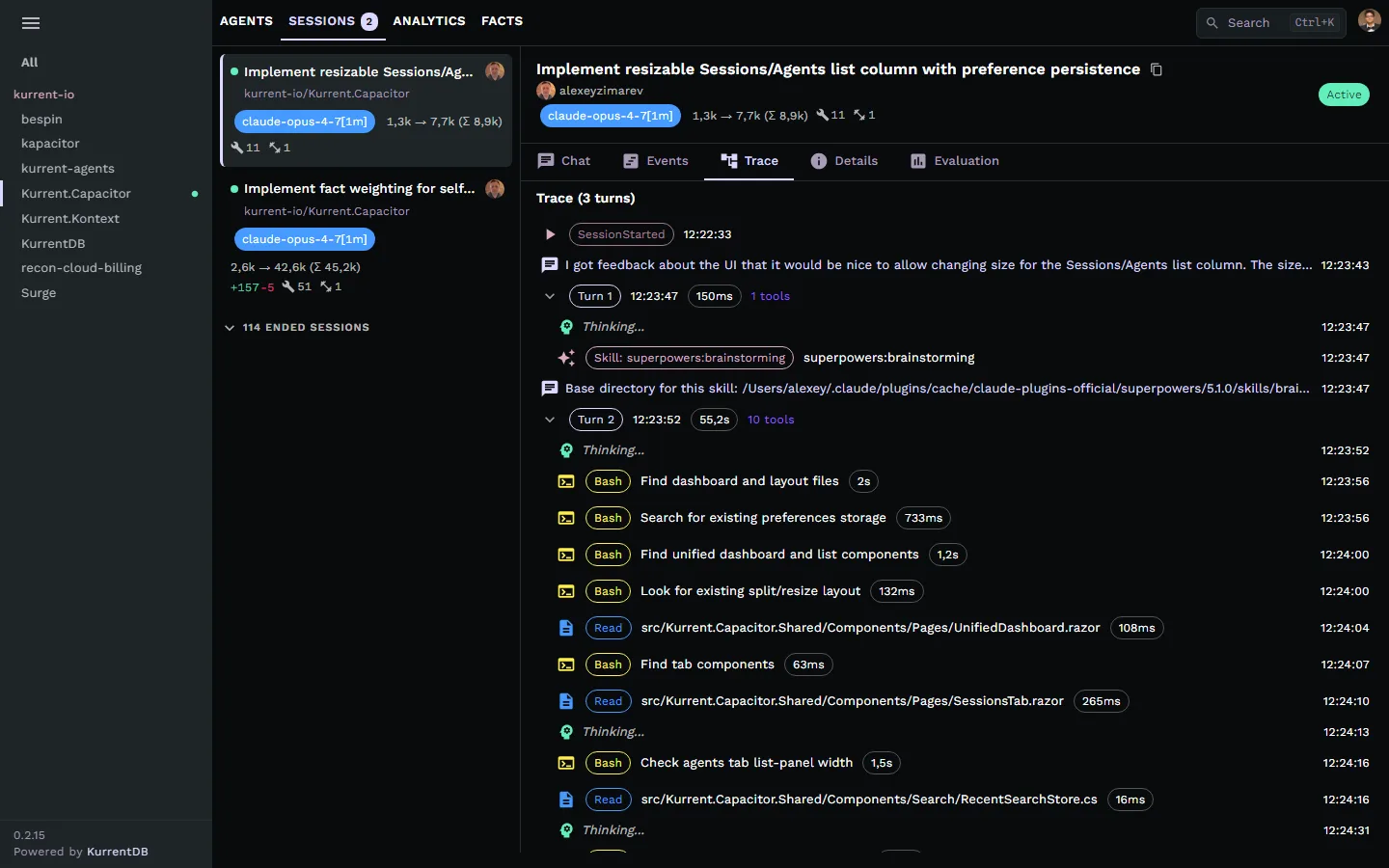
Browse by project
Every repo, every session, one sidebar.
The sidebar groups sessions by GitHub repository. Click a repo to scope the session list to that project. Live status dots show which repos have active sessions running right now.
- Filter to a single repository in one click
- Real-time activity dots when sessions are running
- Token usage, file changes, and tool counts at a glance
Replay the conversation
The whole chat, reconstructed.
The chat view replays the session as it happened: every user prompt, every assistant turn, every code block and diff. Markdown rendering, syntax highlighting, and inlined subagents — exactly the way the dev saw it in their terminal.
- Full conversation with rendered markdown and code
- Subagent runs inlined in the parent timeline
- No need to rerun the agent or pay tokens twice
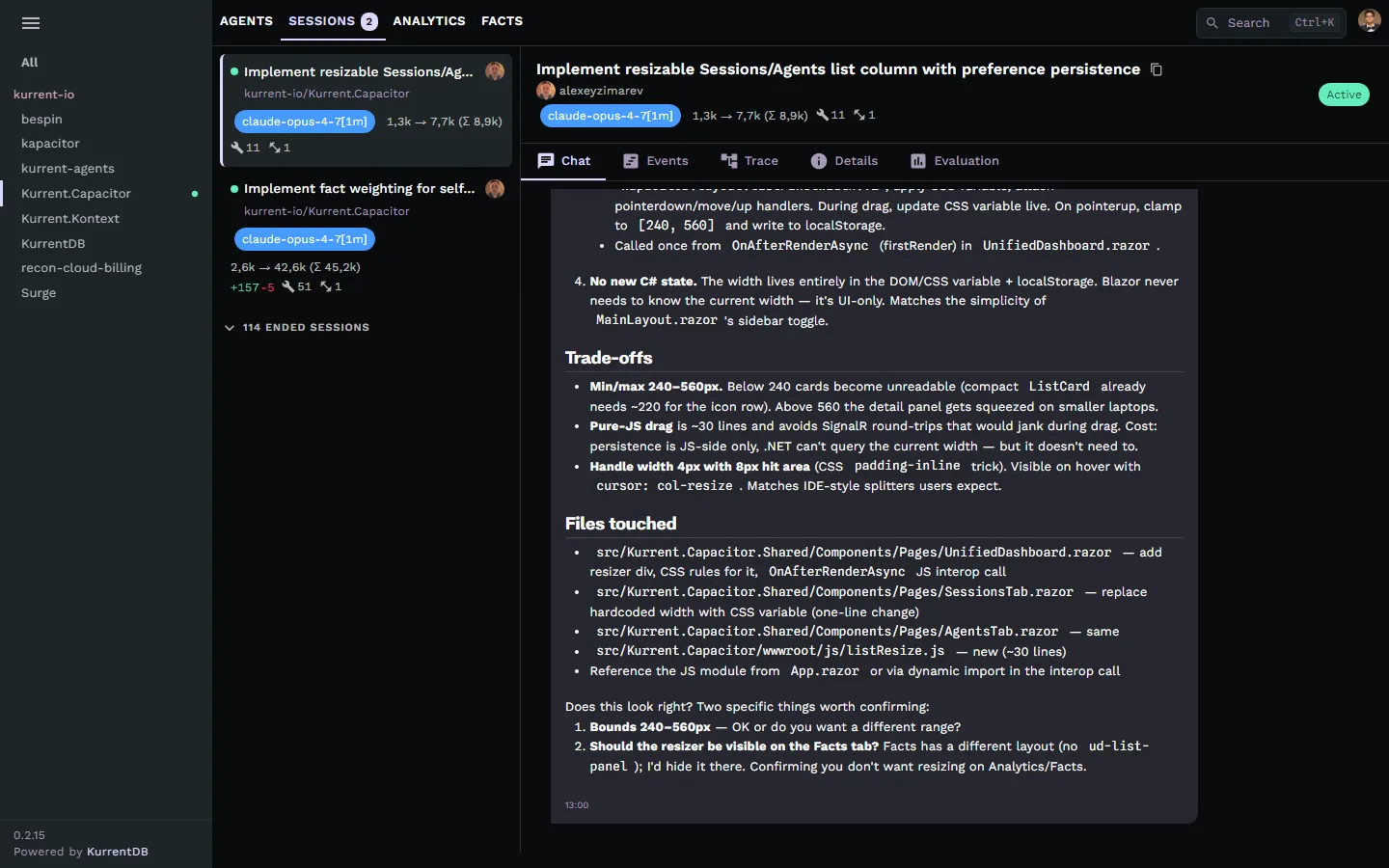
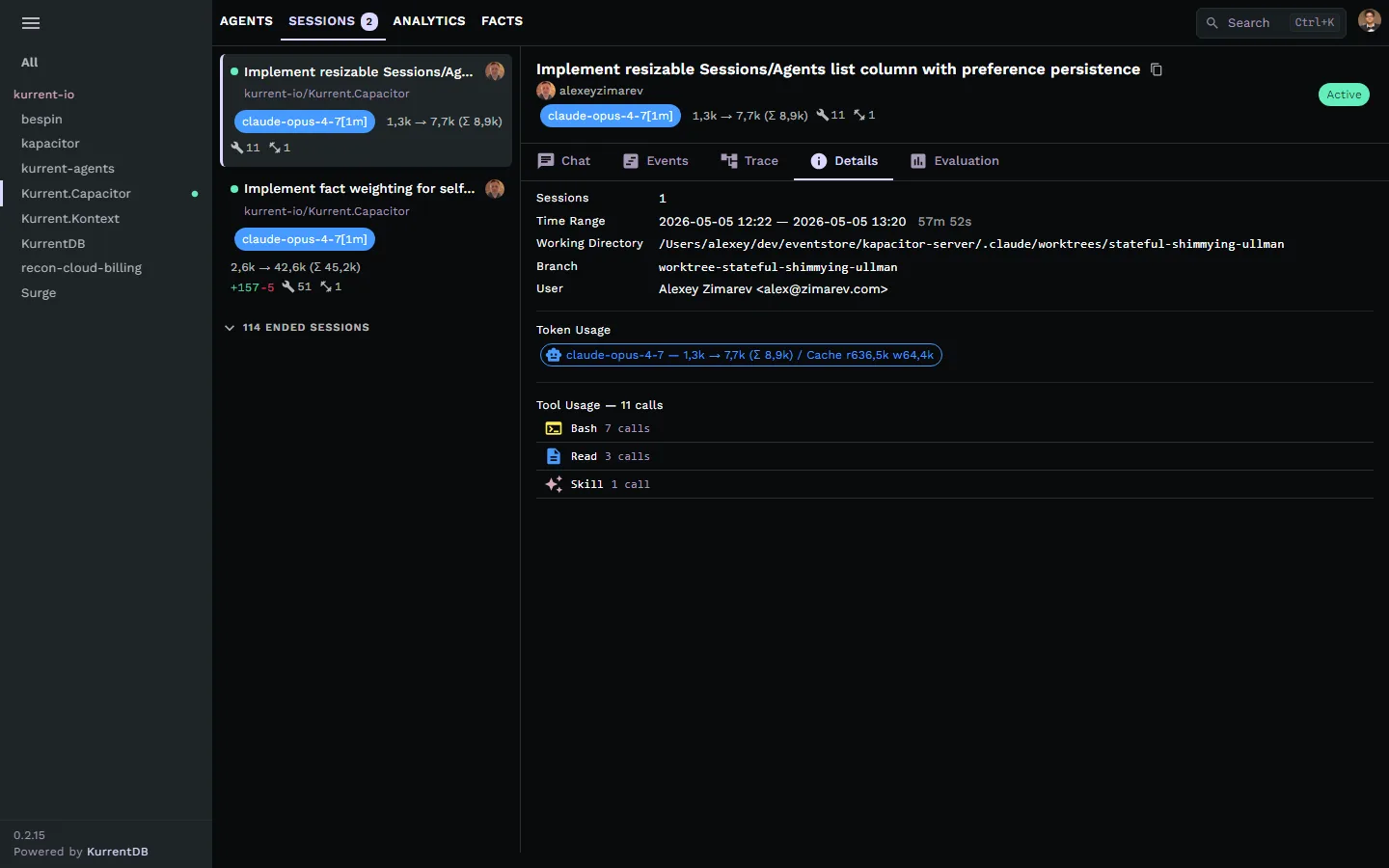
Session stats panel
Tokens, time, and tool calls at a glance.
Every session carries a metadata panel: token usage and cache hits per model, working directory, branch, who ran it, and a tool-call breakdown. Quickly answer "how much did this run cost?" or "what tools did it touch?".
- Token in/out and cache hits per model
- Working directory, branch, and user attribution
- Tool-call counts: Bash, Read, Edit, Skill, and more
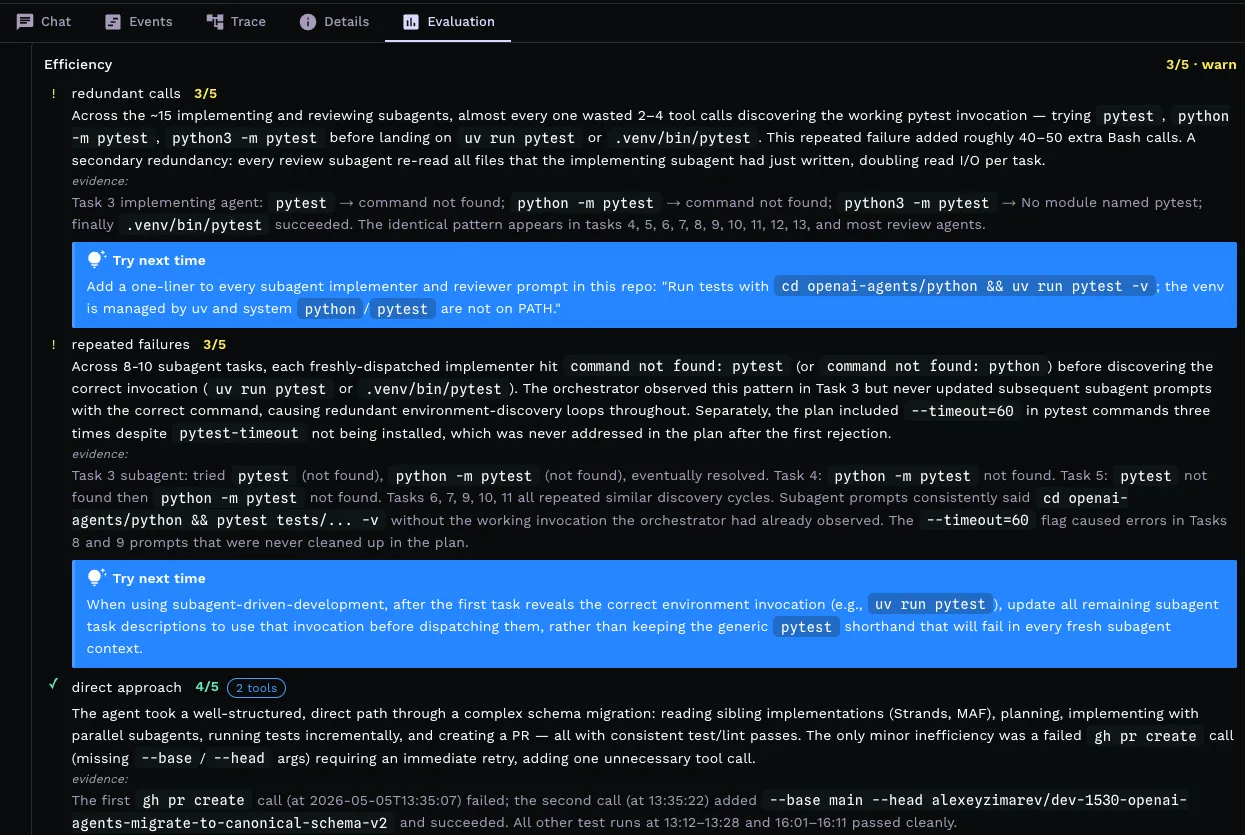
Evaluation
Score every session. Surface what slipped.
Kapacitor runs a structured LLM-as-judge eval against every session: 13 questions across safety, plan adherence, quality, and efficiency, each in its own headless Claude invocation. Some questions inspect the embedded trace; others reach into session-scoped tools to grab the actual test file or untruncated tool output.
- Per-criterion scores with cited evidence
- Findings, recommendations, and a written retrospective
-
Persisted as a
SessionEvalCompletedevent — replayable, auditable, queryable
Built on event sourcing
Every coding-agent hook fires an immutable event into KurrentDB. Sessions, agents, repositories, evaluations, facts — all projected from the stream. Nothing is mutated, nothing is lost, and projections rebuild any time the schema evolves.
Request early access
Kapacitor is rolling out to design-partner orgs. Drop your details and we'll reach out to set up your team.